


What is AWS Redshift or Amazon Redshift
Amazon Redshift

Amazon Redshift is a completely overseen petabyte-scale cloud-based data warehouse product created for large scale data set stockpiling and analysis. It is additionally used to perform large scale database migrations.
Redshift's column-oriented database is intended to associate with SQL-based clients and business intelligence tools, making data accessible to clients in real-time. Based on PostgreSQL 8, Redshift conveys fast performance and efficient querying that assists teams with settling on sound business analyses and decisions.
Every Amazon Redshift data warehouse contains a collection of computing resources (nodes) organized in a cluster. Every Redshift cluster runs its own Redshift engine and contains at least one database.
Features
Exceptionally fast
Redshift is very quick with regards to loading data and querying it for analytical and reporting purposes. Redshift has Massively Parallel Processing (MPP) Architecture which permits you to stack data at bursting quick speed. In addition, utilizing this architecture, Redshift disperses and parallelize your queries over different nodes.
Redshift gives you an alternative to utilize Dense Compute nodes which are SSD based data warehouses. Using this you can run most complex queries in exceptionally less time.
High Performance
As discussed in the previous point, Redshift achieves high performance using extensive parallelism, efficient data compression, query optimization, and distribution.
MPP enables Redshift to parallelize data stacking, backup, and restore operation. Moreover, queries that you execute get distributed over different nodes.
Redshift is a columnar storage database, which is streamlined for massive and repetitive sort of data. Using columnar storage, decreases the I/O operations on disk drastically, improving performance as a result.
Redshift gives you an alternative to defining column-based encoding for data compression. If not specified by the user, redshift naturally allocates compression encoding. Data compression helps in lessening memory footprint and fundamentally improves the I/O speed.
Horizontally Scalable
Scalability is a critical point for any Data warehousing solution and Redshift does truly well job in that. Redshift is horizontally scalable. At whatever point you need to expand the storage or need it to run faster, simply include more nodes utilizing AWS console or Cluster API and it will upscale right away.
During this procedure, your current cluster will stay accessible for reading operations so your application remains uninterrupted.
During the scaling operation, Redshift moves data parallelly between compute nodes of old and new clusters. Subsequently enabling the transition to finish easily and as fast as possible.
Massive Storage Capacity
As expected from a Data warehousing solution, Redshift gives enormous storage capacity. A basic setup can give you a petabyte scope of data stockpiling/storage. Furthermore, Redshift gives you a choice to pick Dense Storage sort of compute nodes which can give enormous storage space utilizing Hard Disk Drives for a very low cost. You can additionally increase the storage by adding more nodes to your cluster and it can work out positively past petabyte of the data range.
Attractive and transparent pricing
Pricing is an exceptionally strong point for Redshift, it is considerably less expensive than other options or an on-premise solution. Redshift has 2 pricing models, pay as you go and reserved instance. Subsequently, this gives you the flexibility to arrange this expense as an operational expense or capital expense.
If your use case requires more data storage, then within 3 years reserved instance Dense Storage plan, viable cost per terabyte every year can be as low as $935. Comparing this with traditional on-premise storage, which generally costs around $19k-$25k per terabyte, Redshift is significantly less expensive.
SQL interface
Redshift Query Engine is based on ParAccel which has a similar interface as PostgreSQL If you are already familiar with SQL, you don't have to get familiar with a lot of new techs to begin using query module of Redshift. Since Redshift uses SQL, it works with existing Postgres JDBC/ODBC drivers, promptly interfacing with the majority of the Business Intelligence tools.
AWS Ecosystem
Numerous businesses are running their infrastructure on AWS as of now, EC2 for servers, S3 for long term storage, RDS for database, and this number is continually expanding. Redshift works quite well if the remainder of your infra is already on AWS and you get the advantage of data locality and the cost of data transport is comparatively low. For a ton of organizations, S3 has become the de-facto destination for cloud storage. Since Redshift is virtually co-situated with S3 and it can get to formatted data on S3 with single COPY command. When loading or dumping data on S3, Redshift uses Massive Parallel Processing which can move data at an exceptionally fast speed.
Security
Amazon Redshift comes stuffed with different security highlights. There are choices like VPC for network isolation, different approaches to deal with access control, data encryption, etc. Data encryption option is available at different places in Redshift. To encrypt data stored away in your cluster you can enable cluster encryption at the hour of propelling the cluster. Additionally, to encrypt data in transit, you can enable SSL encryption. When loading data from S3, redshift permits you to use either server-side encryption or client-side encryption. At last, at the time of loading data, S3 or Redshift copy command handles the decryption respectively.
Amazon Redshift clusters can be launched inside your framework Virtual Private Cloud (VPC). Thus you can define VPC security groups to limit inbound or outbound access to your redshift clusters.
Using the robust Access Control system of AWS, you can concede benefit to specific clients or maintain access on specific database level. Furthermore, you can even define clients and groups to approach explicit data in tables.
Data Lake Integration in Redshift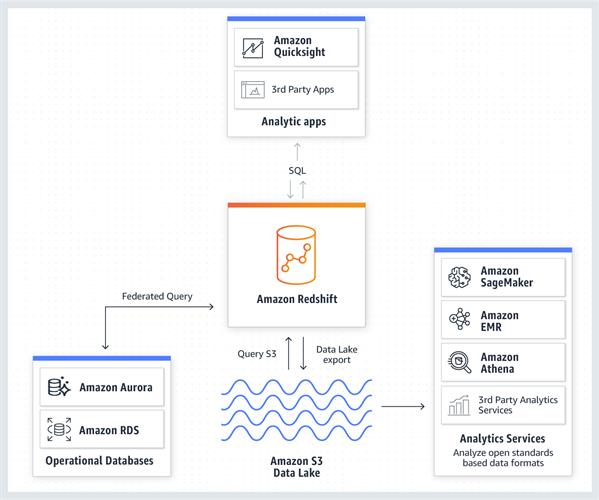
Use cases
Business intelligence
Redshift makes it easy and cost-efficient to run high performance queries on petabytes of organized data so that you can create ground-breaking reports and dashboards using your current business intelligence tools.
Operational analytics ono business events
Unite organized data from your data warehouse and semi-structured data like application logs from your S3 data lake to get real-time operational insights on your applications and systems.
Leading Customers using Amazon Redshift
 |
 |
 |
 |
 |
 |
 |
 |
 |
