


BIG DATA - ( PART 1)
INTRODUCTION
Big Data refers to the large volume of structured and unstructured data. The analysis of big data leads to recognization of pattern and business trends that help to make a better decision.
Data is growing at an exponential rate every year and it is evident by the statement by IBM.
IBM reported that 2.5 billion gigabytes of data were generated every day in 2012. It is predicted that by 2020:
• About 1.7 megabytes of new information will be generated for every human, every second
• 40,000 search queries will be performed on Google every second
• 300 hours of video will be uploaded to YouTube every minute
• 31.25 million messages will be sent and 2.77 million videos viewed by Facebook users
• 80% of photos will be taken on smartphones
• At least a third of all data will pass through Cloud
As the data started to grow rapidly a series of computers were employed to do the analysis.
Distributed Systems
A distributed system is a model in which components located on networked computers communicate and coordinate their actions by passing messages.
Challenges
- Limited bandwidth
- High programming complexity
- High chances of system failure
All these challenges are resolved by using Hadoop.
Hadoop
Apache Hadoop is an open-source distributed framework used to handle and process enormous datasets across clusters of computers using simple programming models.
Characteristics
1. Scalable: It supports both horizontal and vertical scaling.
2. Flexible: It stores a large number of data and enables you to use later.
3. Accessible: Hadoop runs on large clusters of commodity hardware.
4. Simple: It allows users to write efficient parallel code.
5. Robust: As it is intended to run on commodity hardware, it is architected with the assumption of a frequent hardware breakdown. It elegantly handles most of the failures.
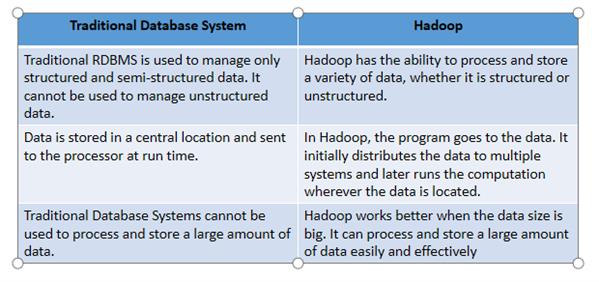
Difference between Traditional Database System and Hadoop
Hadoop supports both structured and unstructured data. This also supports a variety of data formats in real-time such as JSON, XML, and text-based flat-file formats. The traditional database system works well with structured data. Hadoop will be the choice when will need a framework for big data processing on which data being processed does not have a consistent relationship. If the data size is too big for complex processing, or not easy to define relationships between the data then Hadoop will be the choice because it will be difficult to save the extracted information in a traditional database system with a coherent relationship.
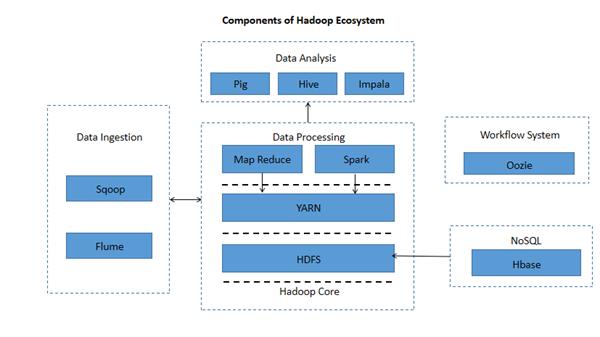
Components of Hadoop Ecosystem
1. Hadoop Distributed File System(HDFS)
2. YARN
3. Hadoop Map Reduce
4. Spark
5. Data Analysis-
- Apache Hive
- Apace Pig
- Apache Impala
6. Data Ingestion-
- Apache Sqoop
- Apache Flume
7. Oozie
8. Hbase
HDFS
It is the most important component of the Hadoop Ecosystem. Hadoop distributed file system (HDFS) is the primary storage system of Hadoop. HDFS is a java based file system that provides scalable, fault tolerance, reliable and cost-efficient data storage for Big Data.
- It provides file permissions, authentication, and streaming access to file system data.
- HDFS is a storage layer of Hadoop suitable for distributed storage and processing.
- HDFS maintains all the coordination between the clusters and hardware, thus working at the heart of the system.
Hbase
Apache Hbase is a NoSql database component of the Hadoop Ecosystem which is a distributed database designed to store structured data in tables. Hbase is a distributed, scalable database that is built on top of HDFS.
- It provides support to a high volume of data and high throughput.
- It is used when you need random, realtime read/write access to your big data.
Map Reduce
MapReduce is a processing technique and programming model for the distributed system. It is a simultaneous process and analyzes massive datasets logically into separate clusters. Hadoop can run MapReduce programs written in different languages- Java, Python, Ruby, and C++. While Map sorts the data, Reduce segregates it into logical clusters.
- It is based on the map and reduces the programming model.
- It has an extensive and mature fault tolerance.
- Hive and Pig are built on the map-reduce model.
YARN
Hadoop YARN (Yet Another Resource Negotiator) is a Hadoop ecosystem component that provides resource management. It monitors and manages workloads, a multi-tenant environment, high availability features of Hadoop, and implements security controls.
- Low operational cost
- Reduces data motion
- High cluster utilization
Spark
Apache Spark is an open-source distributed cluster-computing framework. It is a framework for real-time. It is a fast, in-memory processing engine with elegant and development APIs to allow data workers to efficiently execute machine learning, streaming or SQL tasks that require fast iterative access to datasets. It provides up to 100 times faster performance for few applications with in-memory primitives, as compared to the two-stage disk-based MapReduce paradigm of Hadoop.
- Spark is an open-source cluster computing framework that supports Machine learning, Business intelligence, Streaming, and Batch processing.
- Spark solves similar problems as Hadoop MapReduce does but has a fast in-memory approach and a clean functional style API.
Hive
The Hadoop ecosystem component, Apache Hive, is an open-source data warehouse system for querying and analyzing large datasets stored in Hadoop files. It uses a language called HiveQL (HQL), which is similar to SQL. HiveQL automatically translates SQL-like queries into Map Reduce jobs which will execute on Hadoop.
- Hive is an abstraction layer on top of Hadoop that executes queries using MapReduce.
- It is preferred for data processing and ETL (Extract Transform Load) and ad hoc queries.
Pig
Apache Pig was developed by Yahoo which works on a Pig Latin language similar to SQL. It is a platform for structuring the data flow, processing and analyzing huge data sets.
- Once the data is processed, it is analyzed using an open-source high-level dataflow system called Pig.
- Pig converts its scripts to Map and Reduce code to reduce the effort of writing complex map-reduce programs.
- Ad-hoc queries like Filter and Join, which are difficult to perform in MapReduce, can be easily done using Pig
Impala
Apache Impala is an MPP (Massive Parallel Processing) SQL query engine for processing huge volumes of data that is stored in a Hadoop cluster. It is an open-source software which is written in C++ and Java. It provides high performance and low latency compared to other SQL engines for Hadoop.
- It is ideal for interactive analysis and has very low latency, which can be measured in milliseconds.
- Impala supports a dialect of SQL, so data in HDFS is modeled as a database table.
Flume
Apache Flume is a system used for moving massive quantities of streaming data into HDFS.
- It has a simple and flexible architecture based on streaming data flows.
- It is robust and fault-tolerant and has tunable reliability mechanisms.
- It uses a simple extensible data model that allows for online analytic application.
Sqoop
Sqoop imports data from external sources into related Hadoop ecosystem components like HDFS, Hbase or Hive. It also exports data from Hadoop to other external sources.
Oozie
Apache Oozie is a workflow scheduler for Hadoop. It is a system that runs the workflow of dependent jobs. Here, users are permitted to create Directed Acyclic Graphs of workflows, which can be run in parallel and sequentially in Hadoop.
Conclusion
- Hadoop is a framework for distributed storage and processing.
- The Hadoop ecosystem includes multiple components that support each stage of big data processing:
• HDFS and HBase store data
• Spark and MapReduce process data
• Pig, Hive, and Impala analyze data
• Flume and Scoop ingest data
• Oozie manages the workflow of Hadoop tasks
